The first greenfield app design project for me while at Thought Machine was to create a home for our external product documentation. Thought Machine's product Vault comprises a core banking platform and a separate payments platform which are deployed to clients into their own cloud environment or via SaaS.
Given the nature of the product, the majority of clients choose to integrate Vault into their wider software estate using a set of public APIs and streaming Kafka topics. As a result the need to present a high quality destination for developer documentation was key to enable a self-service understanding of how the product works and how to integrate with it.
Creator vs. consumer journey
The docs hub, as it became known, is by its nature an entirely content driven application. For this reason before we could consider how to craft a good experience for the content consumer we first needed to consider the content creators.
We needed to know who our content creators are and how can we best enable their workflow. After a set of quick colleague interviews we quickly arrived at the position where we would need to support two types of creator:
1. Engineers that need to document API functionality;
2. Technical writers that write longer form guides and tutorials + edit engineer originated content.
On the workflow side we found that engineers were using the Protobuf language to detail API behaviour. They had also been doing some internal experimentation with open source tools to generate an API reference, such as Slate and Swagger.
Tech writers by contrast were creating content using standard markdown syntax. In both cases files being produced were being committed to our central code repo.
During our investigations we also understood there to be three problems to fix for content creators:
1. API reference docs needed additional content enrichment support to allow for endpoint intros and other notes;
2. The guides and tutorials were lacking a hierarchical structure;
3. The markdown syntax was limited and lacked support for more complex elements such as tables.
Early scoping workshop notes
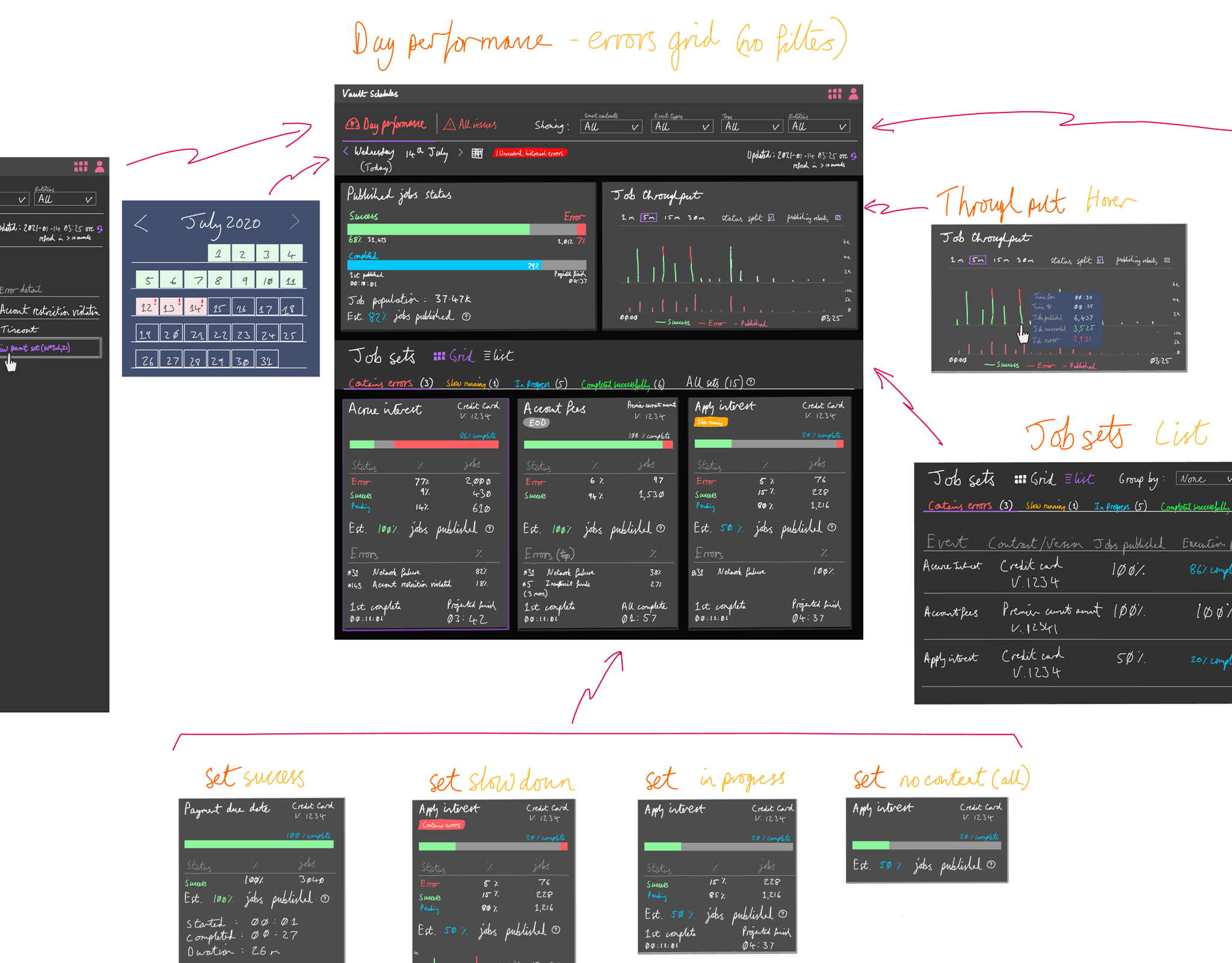
Publishing process
The team now had an idea of the types of content input that we would need to bring together. On the one hand we had generated API reference docs and on the other we had a wide array of markdown based guides & tutorials.
The team made an early implementation decision that we were going to continue to create and store docs content in the code repo. We would then use a set of technologies that would watch certain code folders and generate a static website from them.
We felt the 3 problems discovered above were within reach within our project scope and set about investigating, starting with considering content hierarchy and docs site design in general.
Market analysis
The team did not have much prior experience with designing documentation sites so we knew that the success of the project from the content consumer side would need to largely come down to learning what the audience would need and what is typical/expected from tech docs sites.
Fortunately there was a wealth of publicly accessible examples to mine for best practice. We did a snap colleague survey to gather what people felt were best in class and arrived at the following list:
- Stripe
- Form 3
- AWS
- Vue JS
- Firebase
- Atlassian
- Kotlin
In addition to these we also looked at Thought Machine's open source build framework, Please. The idea was to access from each what we could steal and what to leave behind.

"Leave/steal" consideration of 8 docs sites
Proxying the target user
At the time of doing this project we had yet to establish a client base and as such research direct with target users was not possible. In order to get around this problem we considered that in fact our engineering colleagues and delivery analysts were in fact a good proxy for our users.
As we had a pretty good handle on the problem space we thought to initially do a simple survey with our colleagues in order to establish a few data points to inform the design and shape future validation interactions.
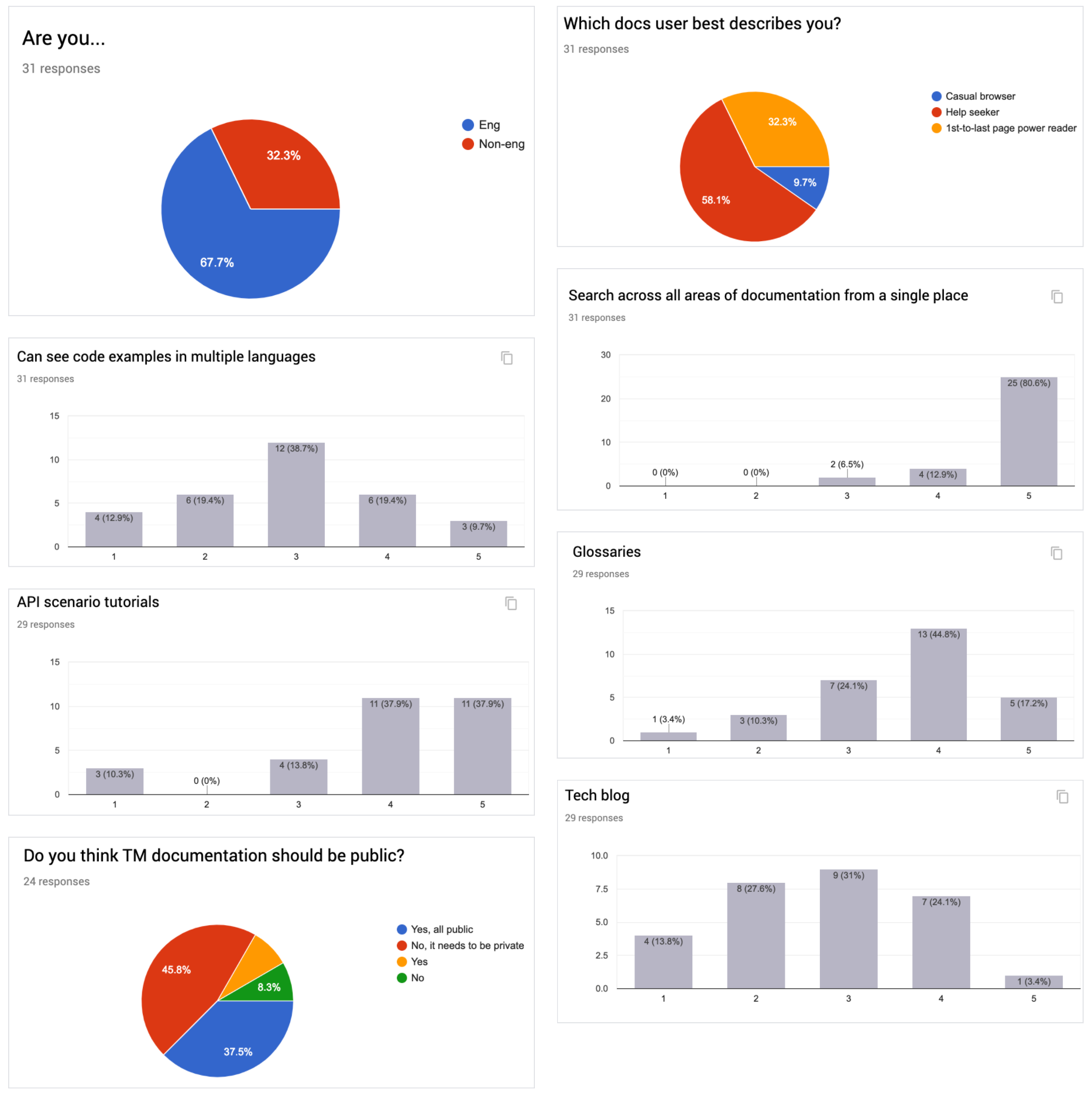
Proxy user survey extract
Assembling our findings
Following on from our lean discovery activity, the team workshopped our respective findings within the categories of: navigation; styling; content & features.
The set of statements we arrived at below are essentially a mix of principles and features which we then used to characterise our 1st version of the docs hub.




Principles & features taken from discovery
Content taxonomy
While we had a pretty good idea what range of content would go into the docs hub we also knew that this would change significantly over time. As such we could not be prescriptive in ways you might expect a typical information architecture to be.
Instead we needed a framework for arranging content and a way for this to be managed in the repo, with the site would be re-generated as part of each product release.
What we can up with was intentionally simplistic.
Content pages would support two levels of integral heading that could be used for in-page navigation. Above the content pages there would be two levels of pure navigational page that could be content enriched.
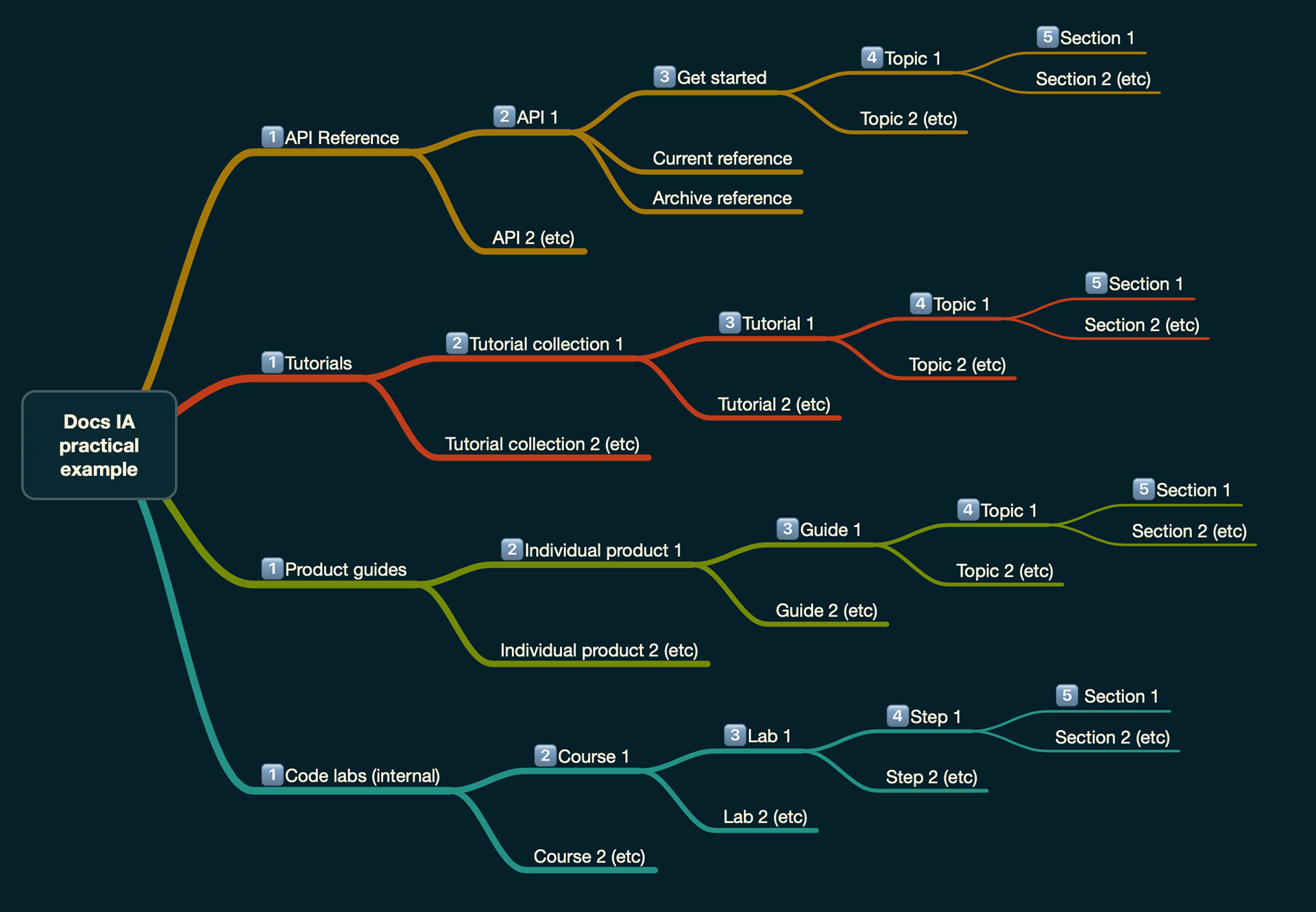
To represent this simplistically we took inspiration from biological classification:
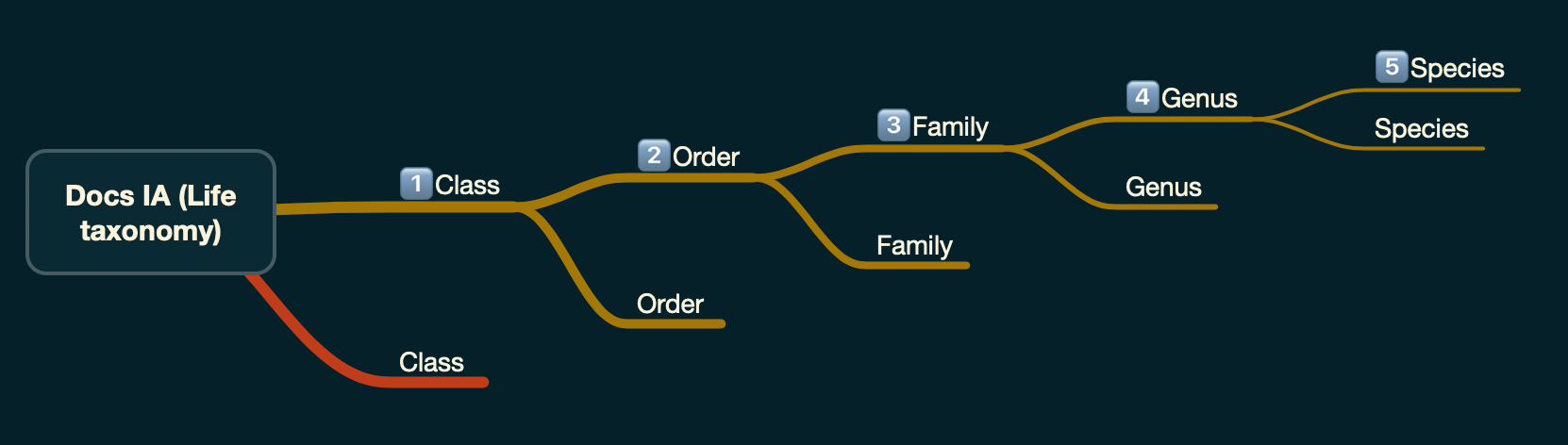
Docs hub taxonomy structure
In practice the API reference docs as well as the markdown files would each be treated as a family. We then introduced syntax to the protobuf files to allow for each endpoint to be treated as a genus and each method within a species.
With the markdown files we used the file name as family with integral H2s genus and H3 species. Lower level headings could also be used at the writer's discretion but would not enter the navigation.
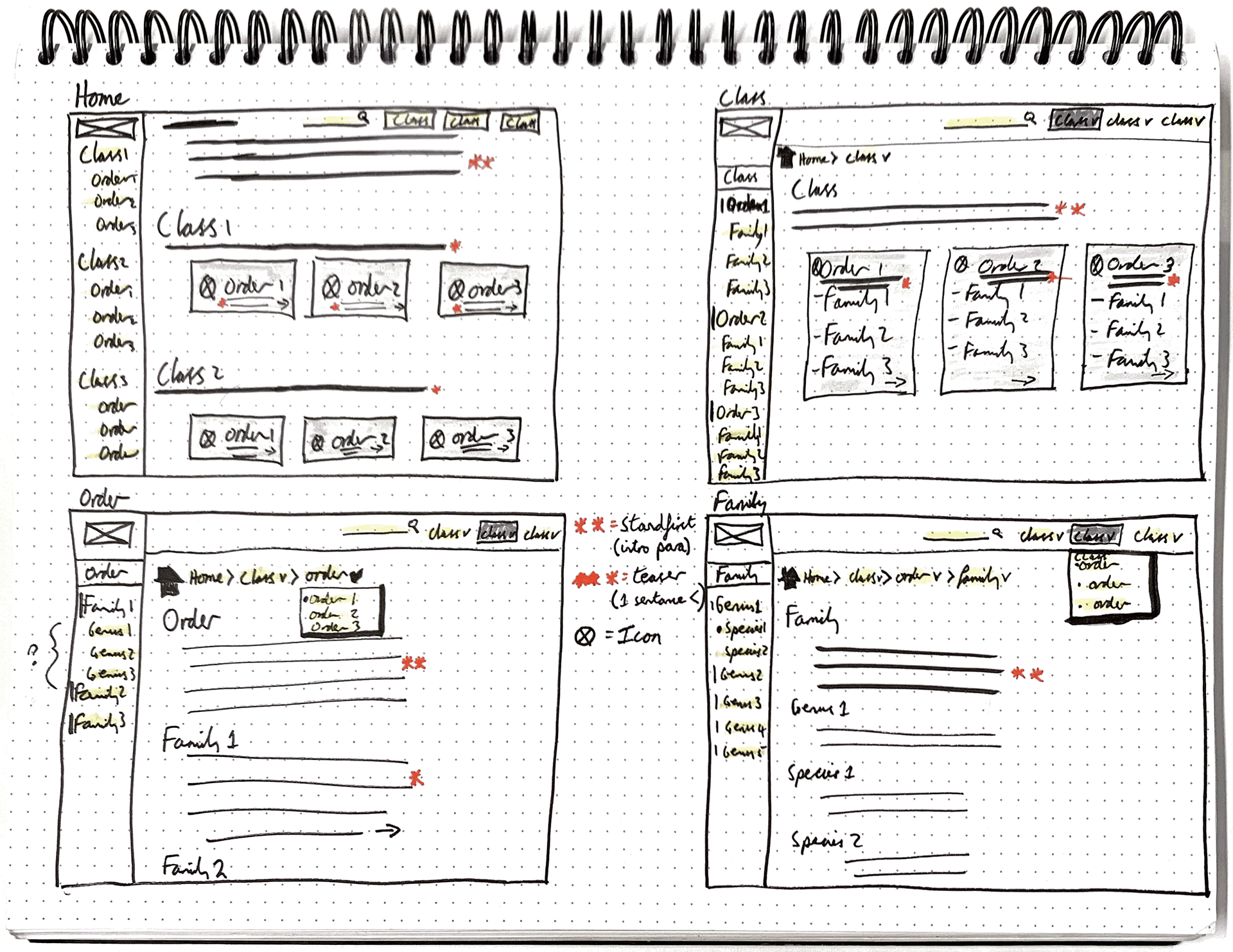
Markdown files were then placed in order folders, which themselves were placed in class folders. We also created special markdown syntax within "sidecar" files that could be used to inject content into both order and class pages.
Early example of docs taxonomy in use
Our other two creator problems
With a plan of how to solve our content hierarchy problem we also needed a way to figure out or other two problems. Namely API reference enrichment and markdown support for complex components.
On the former the solution was pretty simple. First we created support for code comments to be converted into notes within the reference page. Secondly we again created sidecar markdown files where endpoint/method intros could be added using a simple syntax.
On the support for complex components we went back to our tech writers and concluded that basic tables would initially suffice and constructed a basic syntax support for this also.
Application design
Having figured out our architecture we needed to turn our attention to design of the visual layer. Here we were helped greatly by already having a common design system which our team had put in place a few months earlier. We also had many examples of what "good looked like".
The process was fairly simple where we started with lo-fi artefacts which we toured around with a number of colleagues who participated in our survey for feedback.
Lo-fi artefact example
Feedback on these artefacts from our proxy users was positive, as was the feasibility assessment from our tech lead.
From here we created some indicative hi-fi prototypes which ultimately formed the basis of our front-end build.
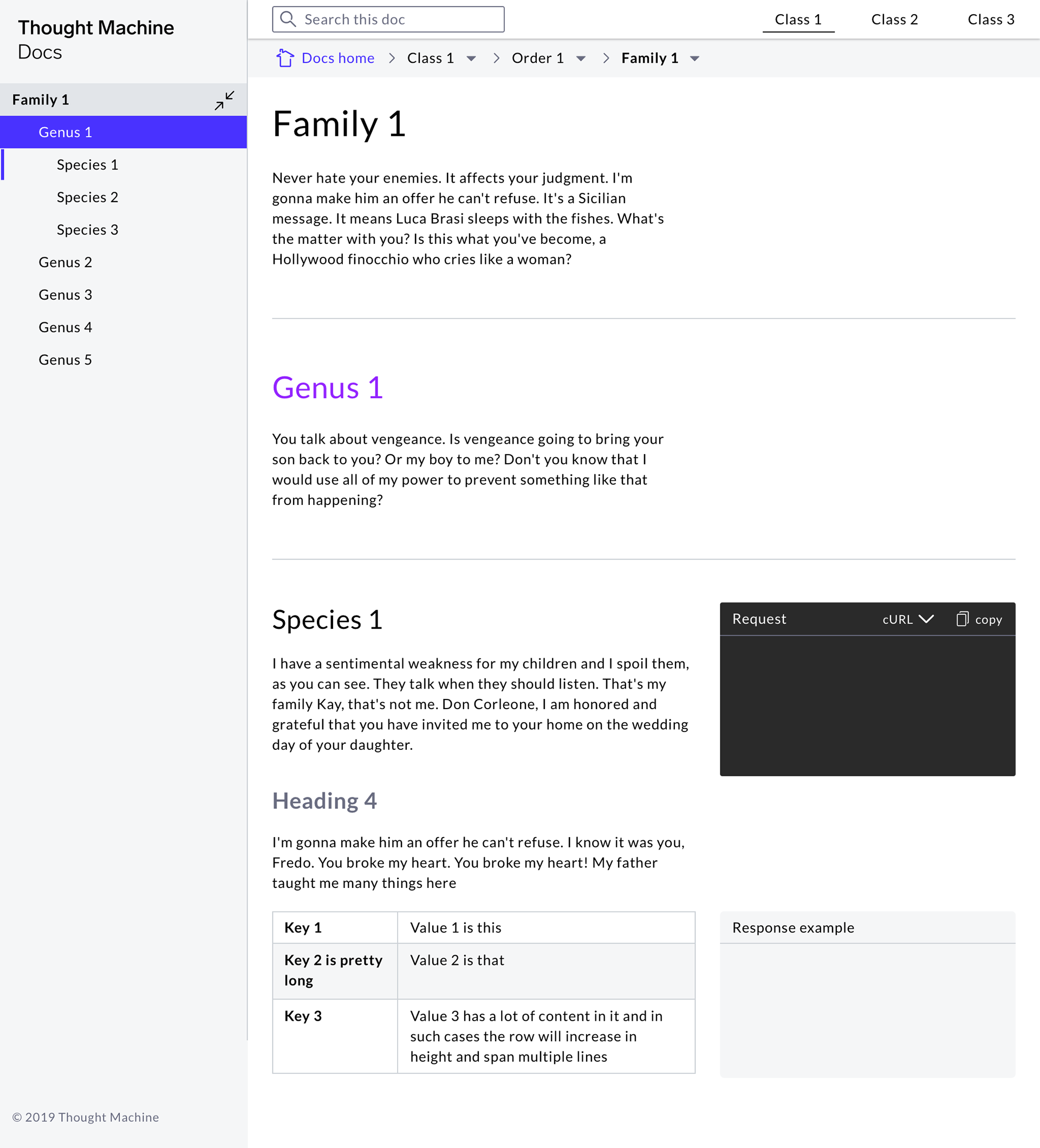
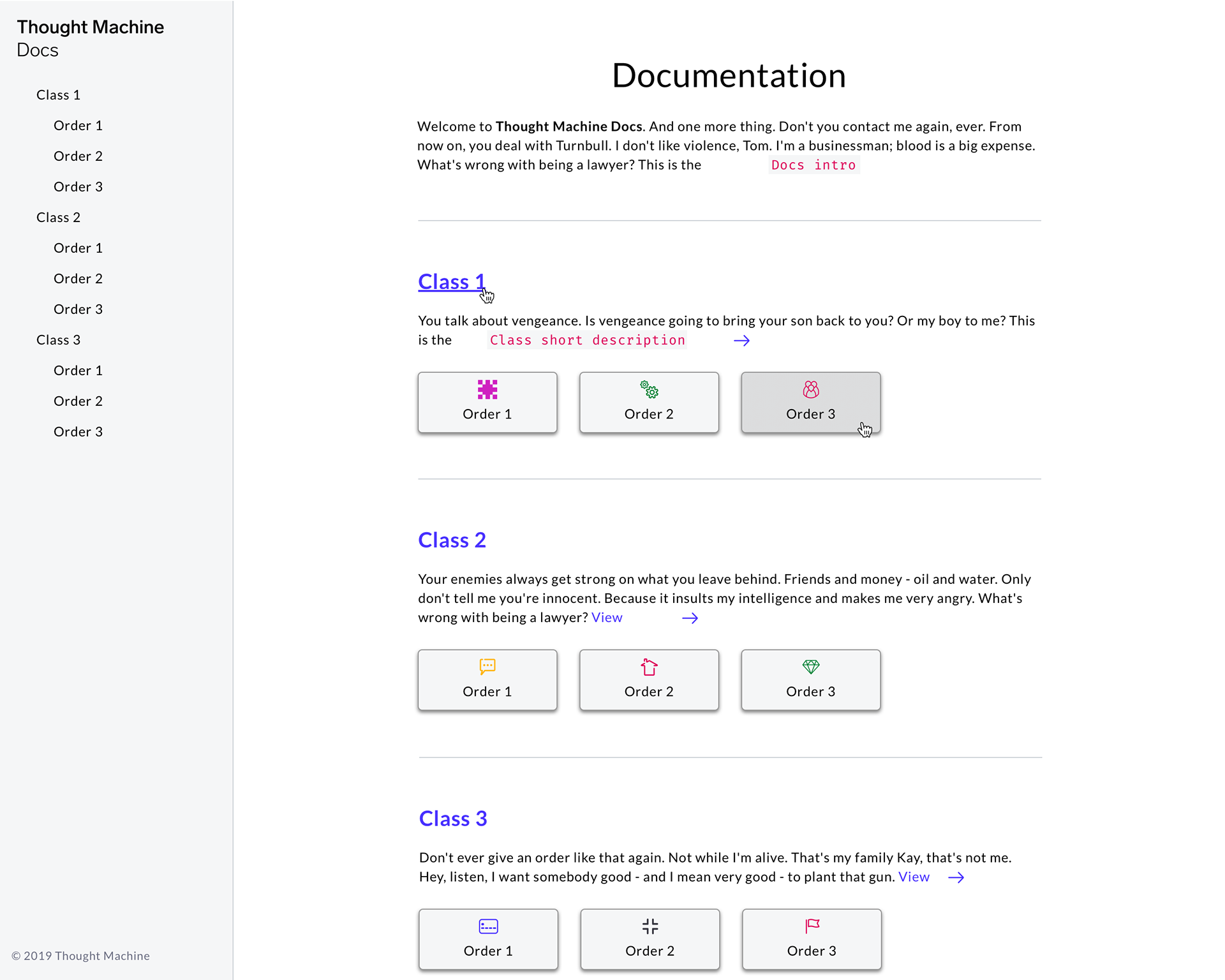
Samples from 1st set of hi-fi designs
The design received minor refinement following a limited series of user testing sessions, again with our internal proxy users.
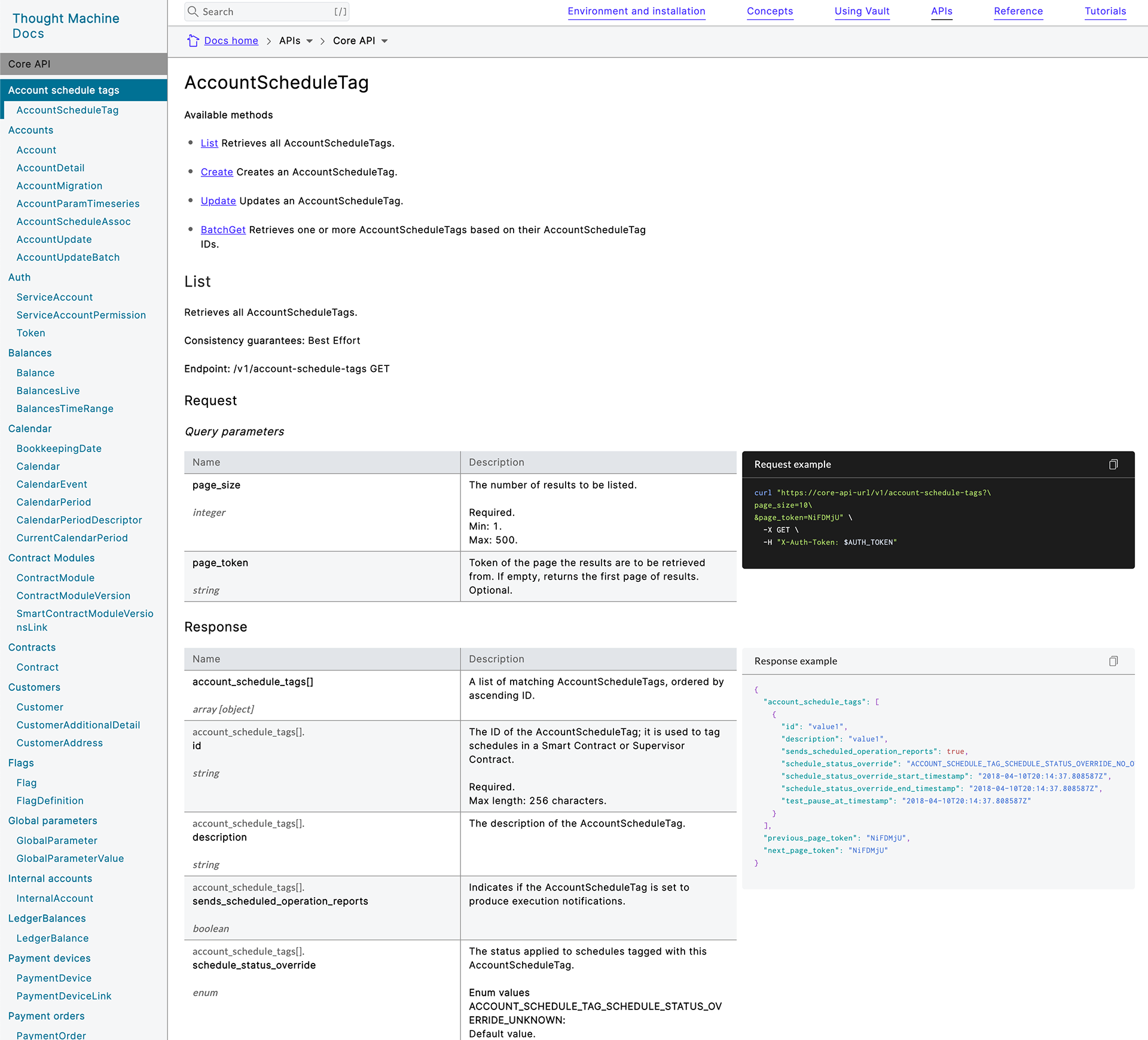
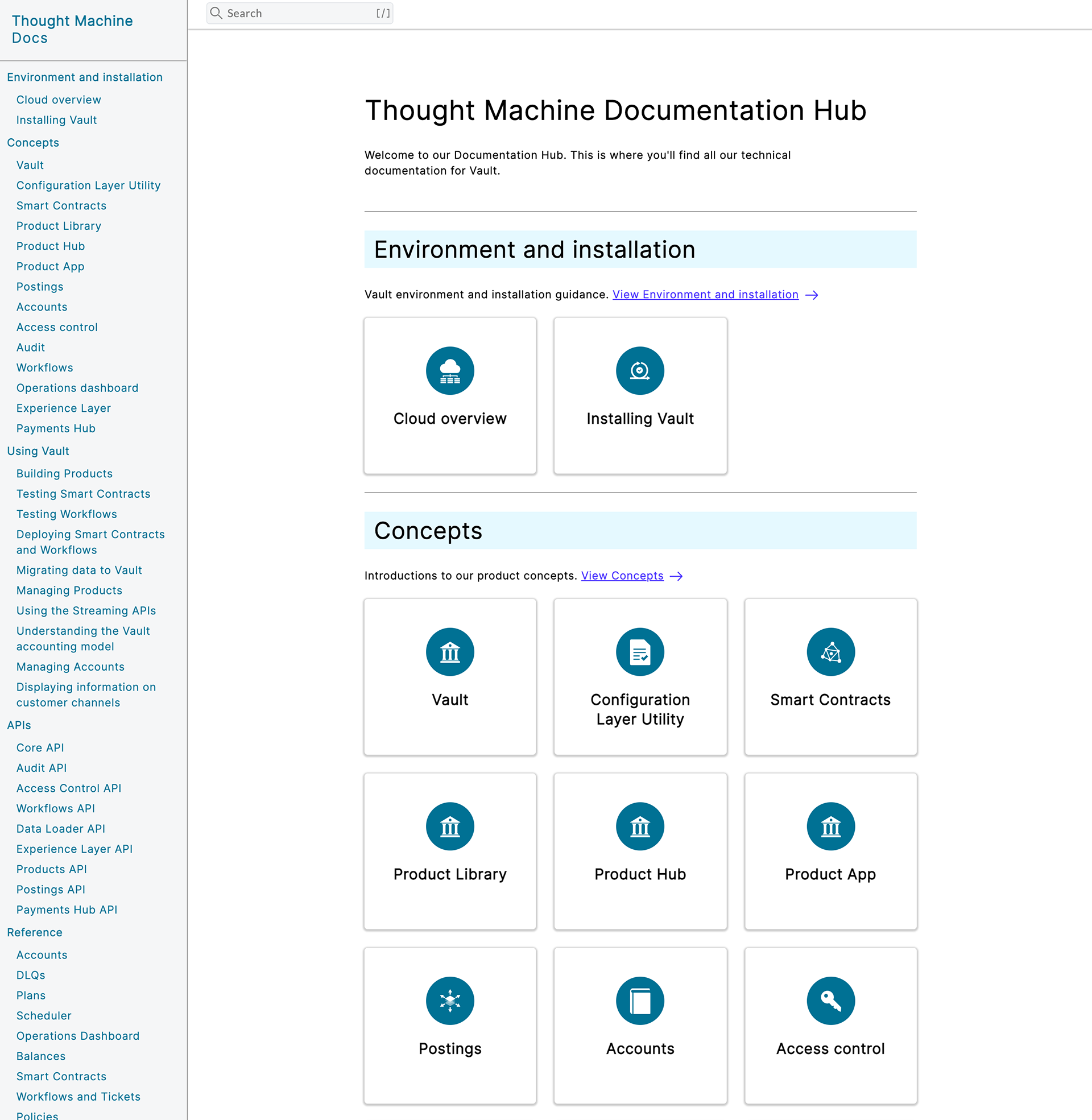
Latest version in production
Retrospective
Looking back at this project there are I think a number of areas where we could have improved our methods.
Perhaps chief among these was that due to competing projects and limited resources, the design team did little follow-on work to assess how the docs hub could be further advanced once in production. Even the dedicated engineering team was relatively short lived, with the assessment internally that the offering was adequately serviceable.
We also I feel fell short in appreciating the usability constraints on the content creator side that are resultant from statically generating the site from content files. In essence it became difficult for content writers to visualise how their content would look within the generated site. The only method to do this would be to locally run an instance of our mono repo code base and do a build/release to see the outcome - which was a lengthy process at the time.
My personal opinion is that we should have better considered the longer term opportunity cost of this provision. If we had we might have concluded that a doc site was not within our core competency and as such a better solution may have been to license an off-the-shelf platform rather than to self build.