Prototyping & feasibility investigations
Having got a green light for the project, the next stage was twofold. First and foremost was to ensure that the aggregation abstraction and subsequent drill down was feasible to implement. Second, on the basis that it was feasible we needed to start thinking about how to craft the UX and ultimately UI for the application.
System of record vs. system of engagement
Early on in our feasibility consideration we had difficulty. The trouble was that the API that we had hoped to leverage for our solution was heavily optimised for database writes, with reads being of secondary concern. This was because as a company we were chasing dramatic improvement in supported number of transactions per second - a key metric for product success.
We realised quickly that the new types of data associations we were looking to create, along with the sort of complex calls that would be core to the experience, would create significant performance drag. Simply put they would not be viable in the current architecture.
What we needed was a different method to access the data, where performance was less of a concern and where complex read support could be baked in from the start. The solution we came up with was to propose the creation of a separate eventually consistent database that would be populated by listening to a select collection of Kafka topics (a form of push messaging feed). We would then create a new API that would be optimised for flexible reads at the cost of less performance.
We knew this would take some effort to build and so made a second set of internal pitches to gauge senior stakeholder support. The response we got was again positive however it was clear we would need to get creative so as to not invest too much in the build before first putting something into the target users hands for usage feedback.
Low fidelity prototypes
We knew that we wanted to prototype in order to get more client validation. While ultimately our goal was to deliver a series of implementation prototypes the team felt that given the complexity and steep cost of full implementation that the right place to start was with low fidelity prototypes.
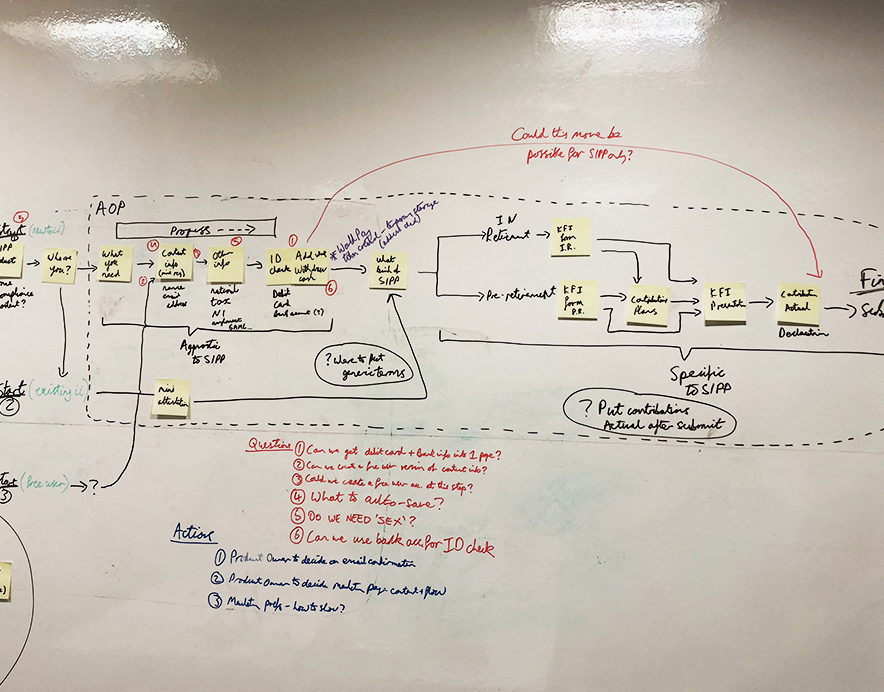
The team had had good prior success with hand drawn artefacts combined with client demo workshops and felt a similar approach could work well here.
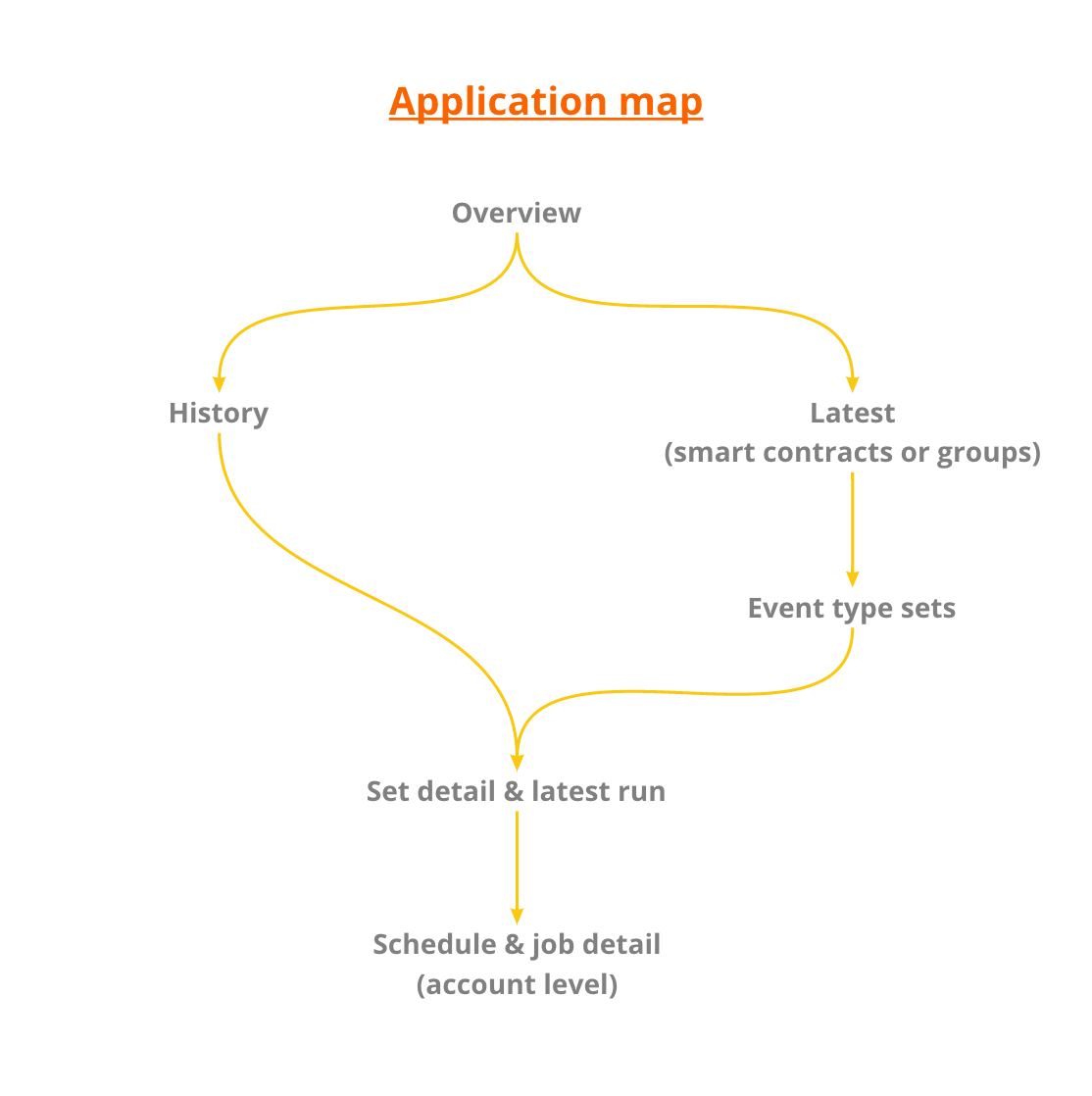
Our first step was to divide and individually consider different patterns for how we might present our journey, starting with our aggregation abstraction onto which we considered various forms of drill down interaction.
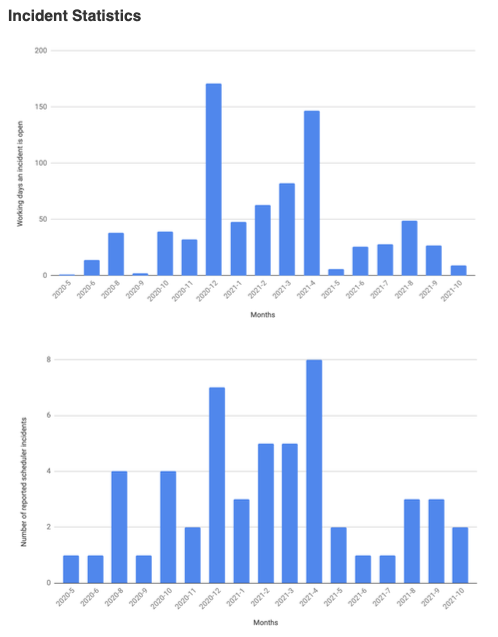
We were also interested in how we might be able to visualise overall health of schedules in order to provide an "at a glance" system check.